第一部分 --- 散列表的基本概念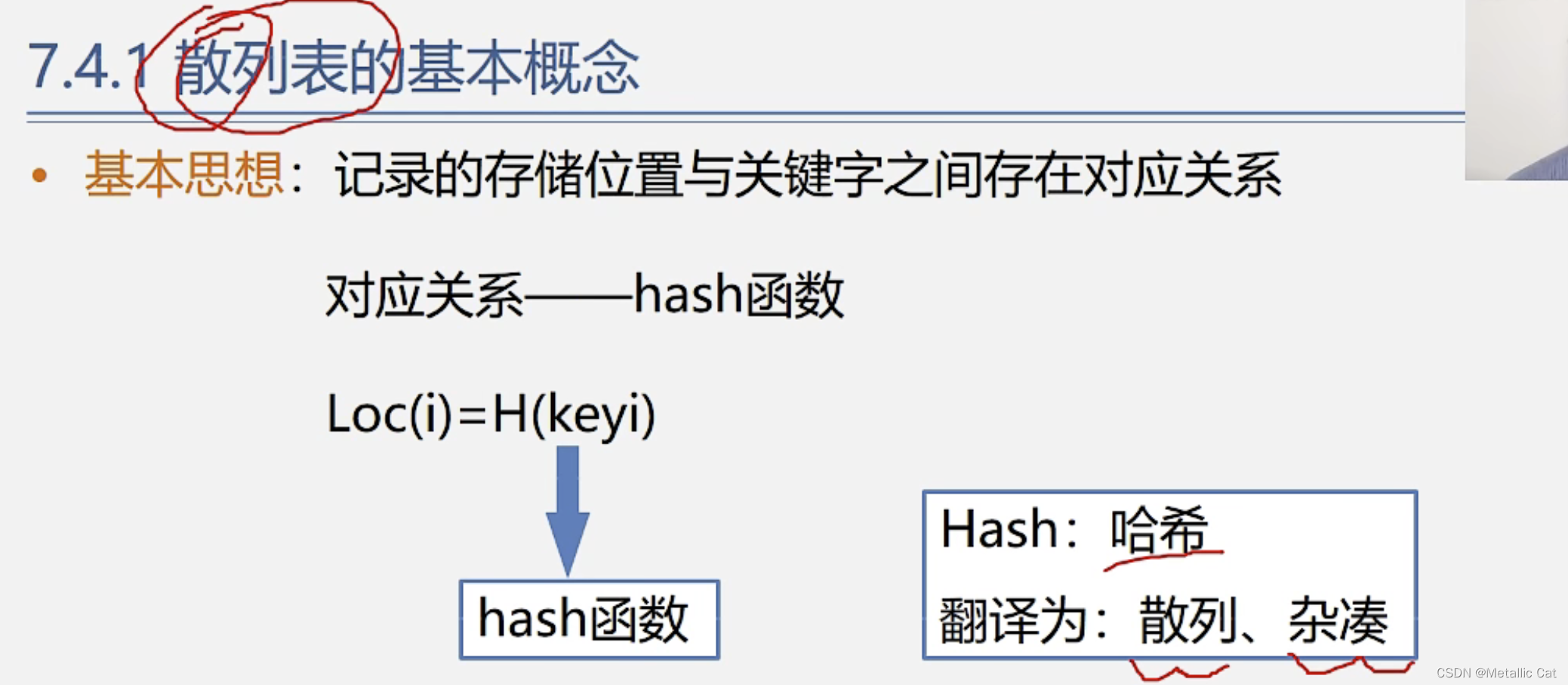
1.在记录表中的记录(元素)的存储位置和记录的关键字之间存在着对应关系,这个对应关系就是hash函数
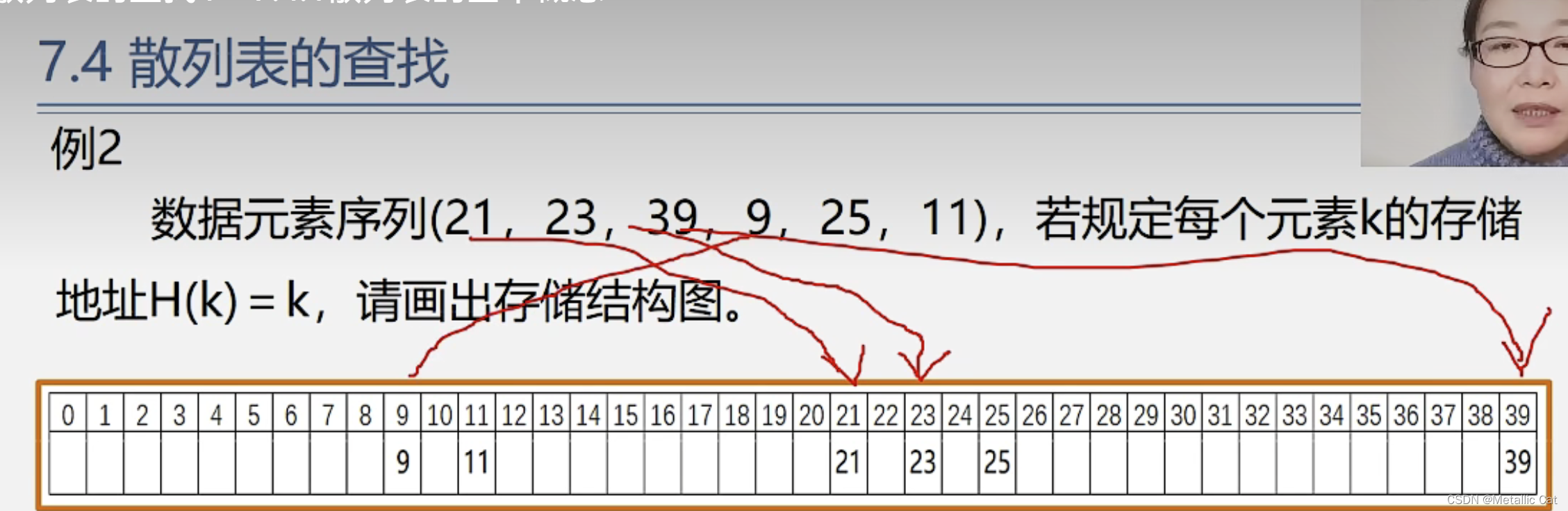
1.通过哈希函数找查找表中的某个元素的存储位置就非常方便了,我们只需要将这个元素的关键字作为参数传给哈希函数,哈希函数在成功将关键字根据对应关系转换为存储位置后,就会转换得到的存储位置(下标),如果转换失败的话一般会返回空指针或者是0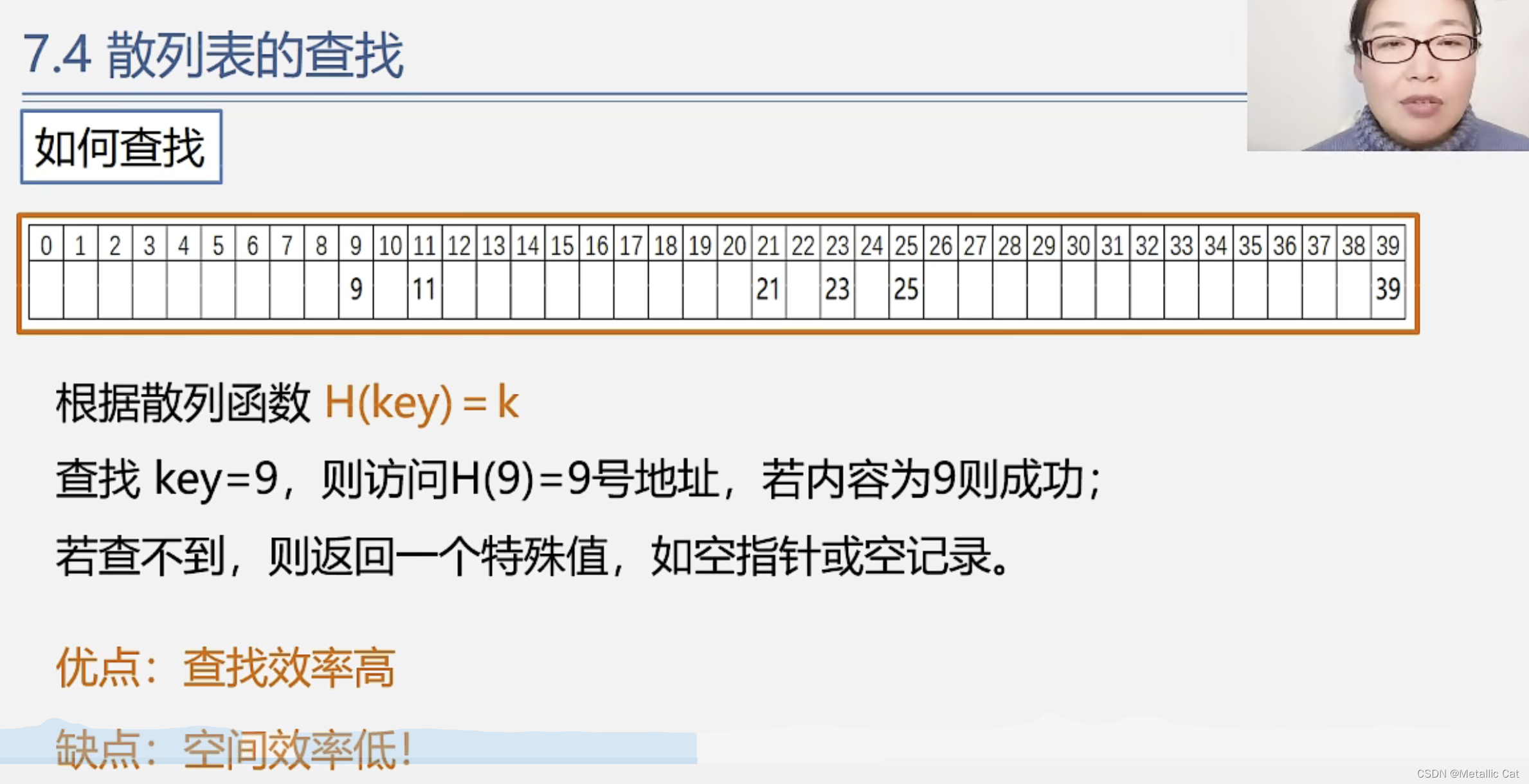
1.能够使用哈希函数查找元素的查找表叫做散列表,往散列表中存储元素的时候,也是通过关键字 + 哈希函数转换得到存储位置(下标)然后进行存储,这种存储方式导致的结果就是查找表的空间利用效率低,但是查找速度块,时间复杂度为O(1) --- 只用执行一次哈希函数即可
1.散列方法就是使用哈希函数来存储元素和查找元素的方法
2.散列函数就是哈希函数,本质上是一个转换器,通过给定的对应关系将关键字转换为散列表中的对应的存储位置
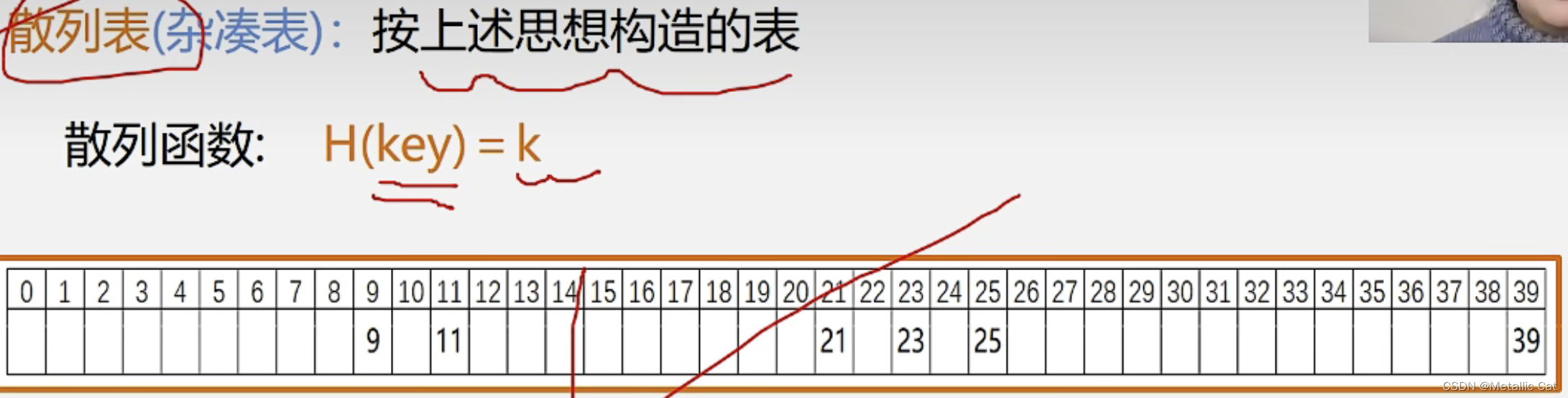
1.通过散列方法存储元素时创建的表就是散列表
1.什么叫冲突:冲突指就是散列表中的一个存储位置有多个元素想要存储(散列表中一个位置只能存一个元素,先到先得)
2.什么是同义词,同义词描述的是多个关键字之间的关系,假设有k个不同关键字,将这k个不同的关键字作为参数传给哈希函数都得到了相同的存储位置的话,则称这k个不同的关键字互为同义词
2.散列表又称为哈希表
第二部分 --- 散列(哈希)函数的构造方法
首先,通过哈希函数来将关键字转换为存储位置时,冲突是不可避免的,我们只能够尽可能的减少冲突,那么怎样才能够有效的减少哈希函数带来的冲突造成的问题?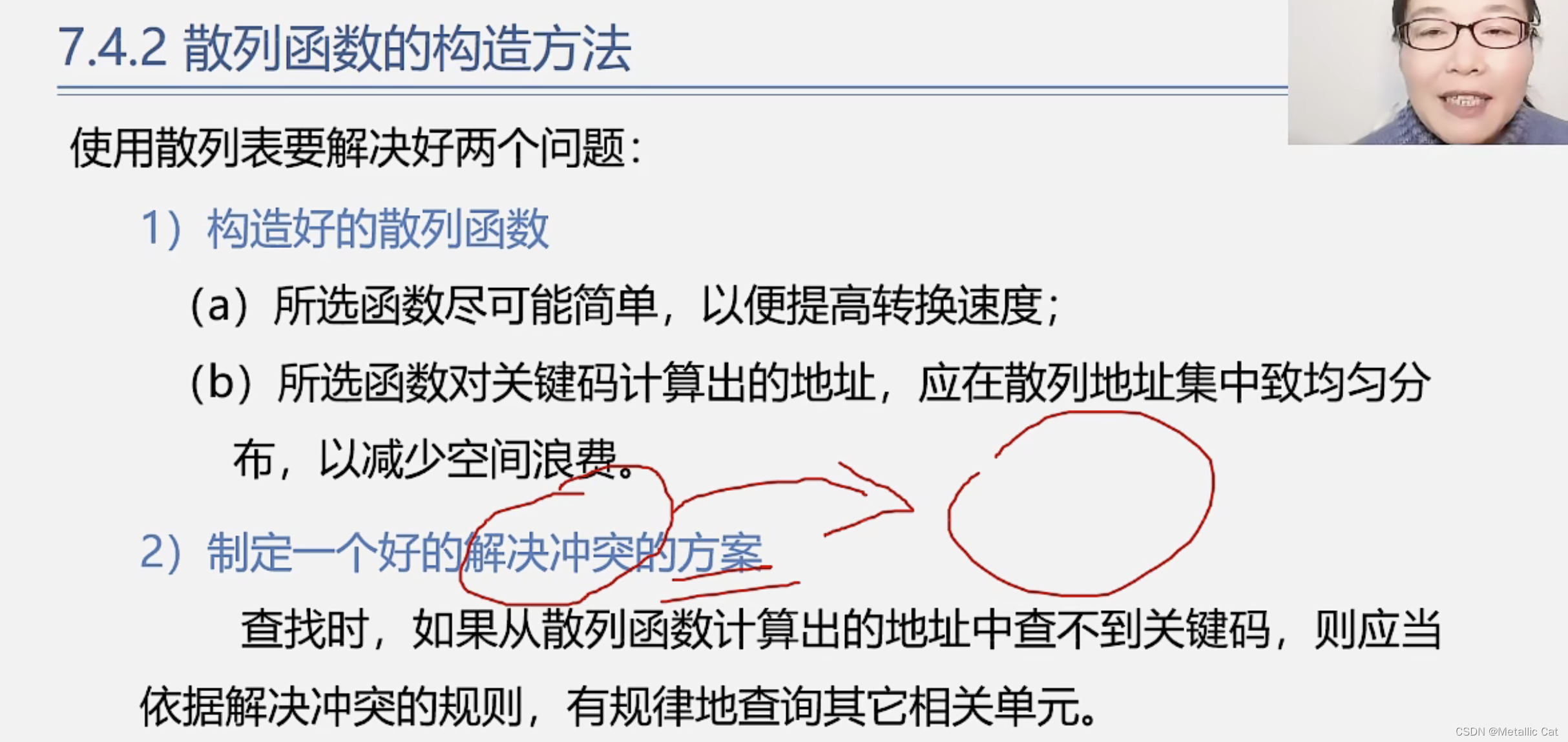
方法一:构造一个好的哈希函数,这个哈希函数(散列函数(转换器))要足够足够高效,简单,稳定,转换速度快,并且通过这个转换器转换出的存储位置要尽可能的均匀分布,如果过密分布可能导致冲突出现,如果过疏分布则可能导致空间浪费
方法二:当冲突不可避免的出现的时候我们要有好的解决冲突的方案,这个方案也需要尽可能的简单,高效和稳定。
(一个是解决问题本身,一个是解决问题)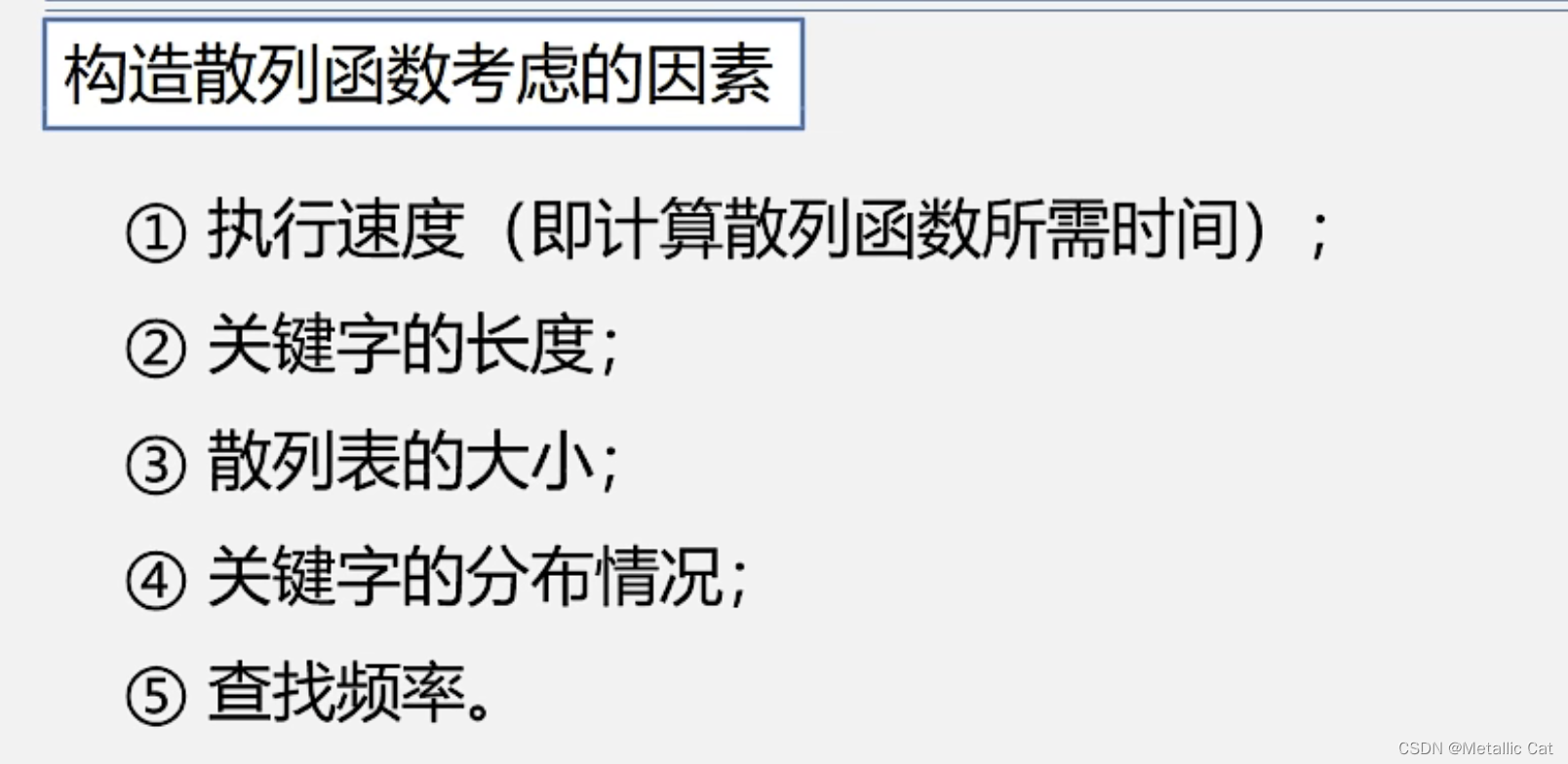

1.有多少个数据就占多少个地址
1.直接定址法采用的是线性函数,线性函数的自变量和因变量一一对应,所以不用考虑冲突的问题

1.质数是只有1和它本身能够整除它的非负整数称为质数
2.上面这个m是关键字序列的长度,这个 p 是尽可能取较大值的质数
第三部分 --- 处理冲突的方法
这里主要介绍两种方法:开放地址法和链地址法
1.开放地址法其实就是在出现冲突的时候,那么我们就在表中找一个新的存储位置来存储元素,如果这个存储位置对应的元素还不为空的话,那就继续存到新的存储位置,直到找到元素为空的存储位置为止(如果找编所有的存储位置都不行的话,那就返回表已满)
2.那么我们获得新的存储位置的方法是什么呢?
我们常常采用除留余数法来获得新的存储位置,使用这个方法的具体步骤是:
一.将通过哈希函数求得的元素不为空的存储位置(下标)作为参数传给这个函数,函数处理完之后就会返回新的存储位置(下标)
(函数的处理方法是将传过来的参数加上一个增量序列,然后将求得的和除以m(m为散列表的长度)并取余,最终的计算结果就是我们要返回的新的存储位置(下标))
二.如果新的存储位置(下标)对应的元素依然不为空的话,我们就通过更改方法中的增量序列(其它值不变)的方式再次获得新的存储位置,如果元素还是不为空,那就继续重复第二步,直到新的存储位置超出了散列表的范围为止
3.根据增量序列的不同,除数取余法又分为三种类型,分别是:
线性探测法,二次探测法,伪随机探测法
线探:第一次求新存储为止时增量序列为1,第二次是2,第三次是3.....一直到第m - 1次为止


查找的时候也同理,如果查找的值的关键字和计算出的存储位置的元素的关键字不同的话,我们就用整数取余法去看其它的存储位置元素,如果还是不相等的话那就继续获取新存储位置来查找,直到找到或者是存储位置超出散列表范围为止
(查找时获得新地址的方法和我们上面插入元素时获得新地址的方法一样)
二次探测法:增量序列第一次探测是1的平方,第二次是 - (1的平方的),第三次是2的平方,第四次则是 - (2的平方)....一直到q的平方为止
伪随机探测法:每一次探测时,增量序列都是我们给的一个伪随机数
1.整数取余法是用来获得新地址的(里面的m等于散列表的长度),除留余数法是用来构造散列函数的,里面的p是最接近关键字序列长度的质数(只能够被1和它本身整除的非负整数)
1.非负整数K mod 非负整数m (即将整数K除以非负整数m后取余)的计算结果的范围是 0到 m -1
1.用开放地址法的时候,可能会出现非同义词之间存在冲突。原因如下:
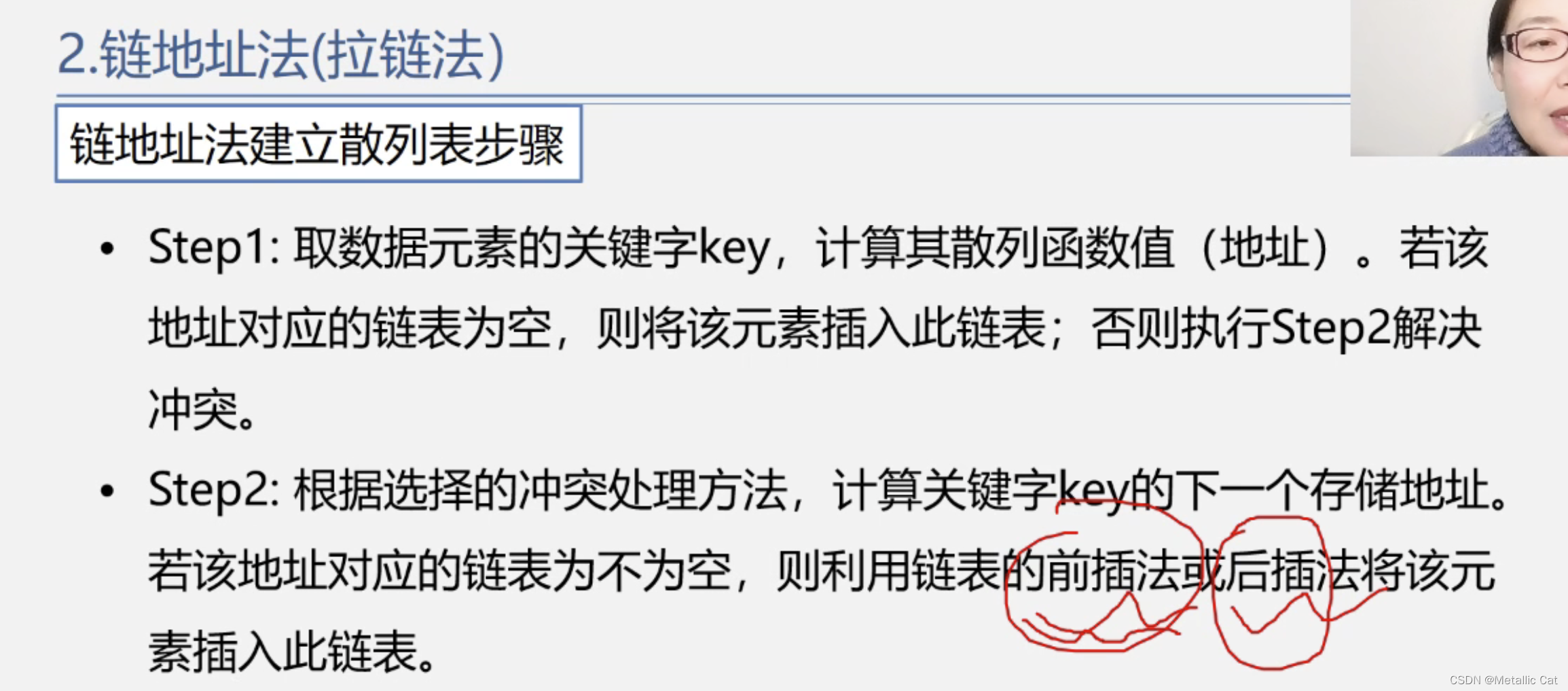
首先是多个同义词之间存在冲突,则我们要找新的且为空的 存储位置来存放没被存放的同义词,在存放好后有一个和同义词不同的的关键字通过散列函数刚好找到这个新的存储位置,此时非同义词之间就会发生冲突(散列表中同一个位置要被多个元素争着存放)
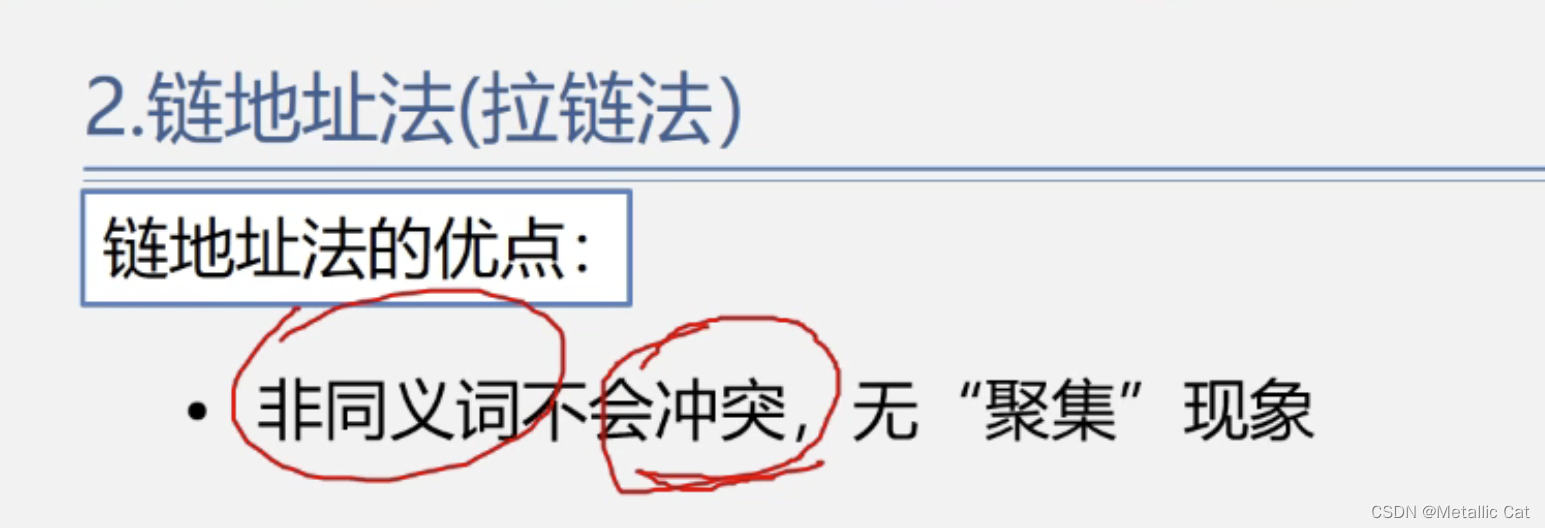
链地址法的缺点也很明显,就是空间浪费严重
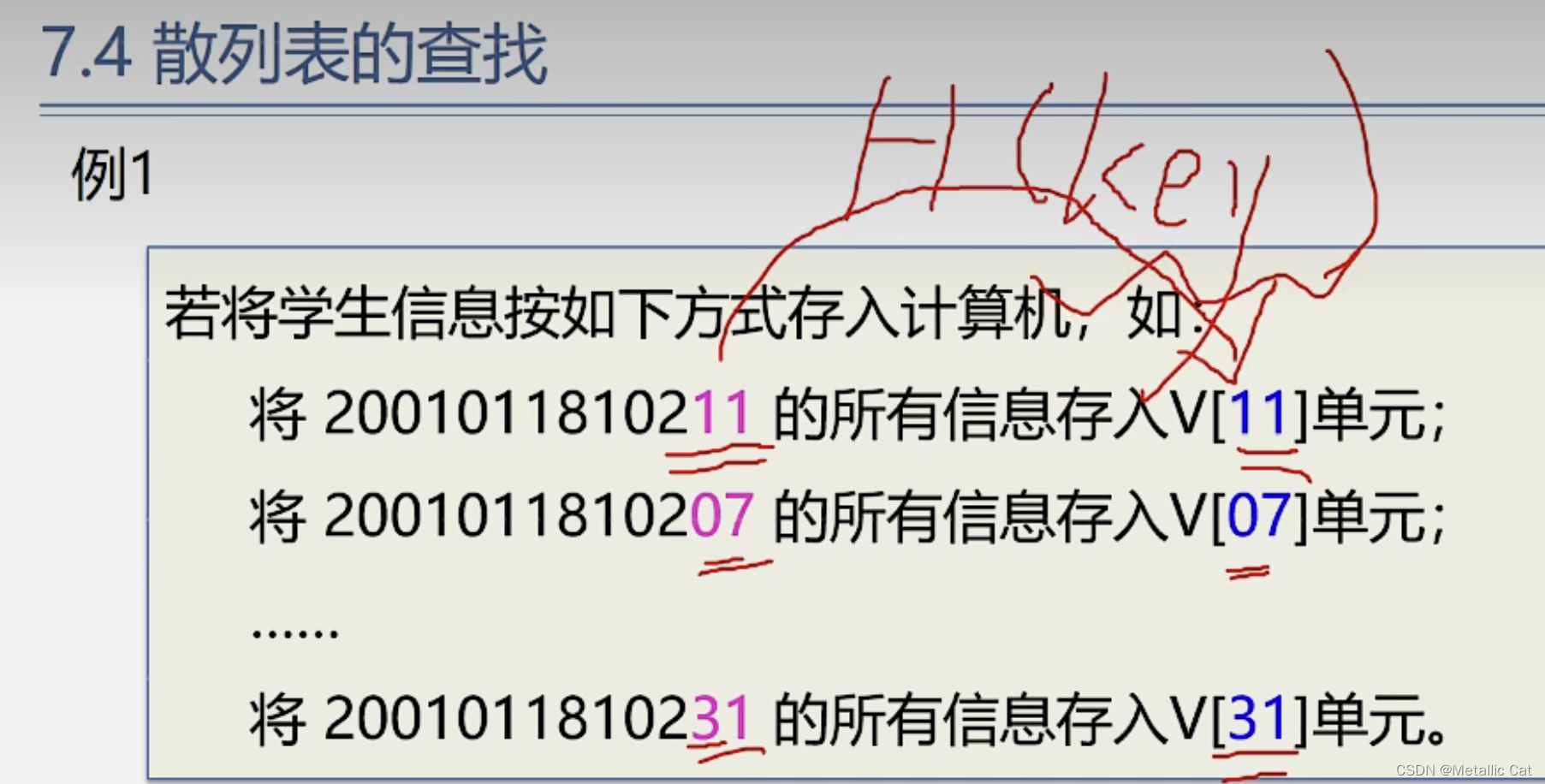
第四部分 --- 散列表的查找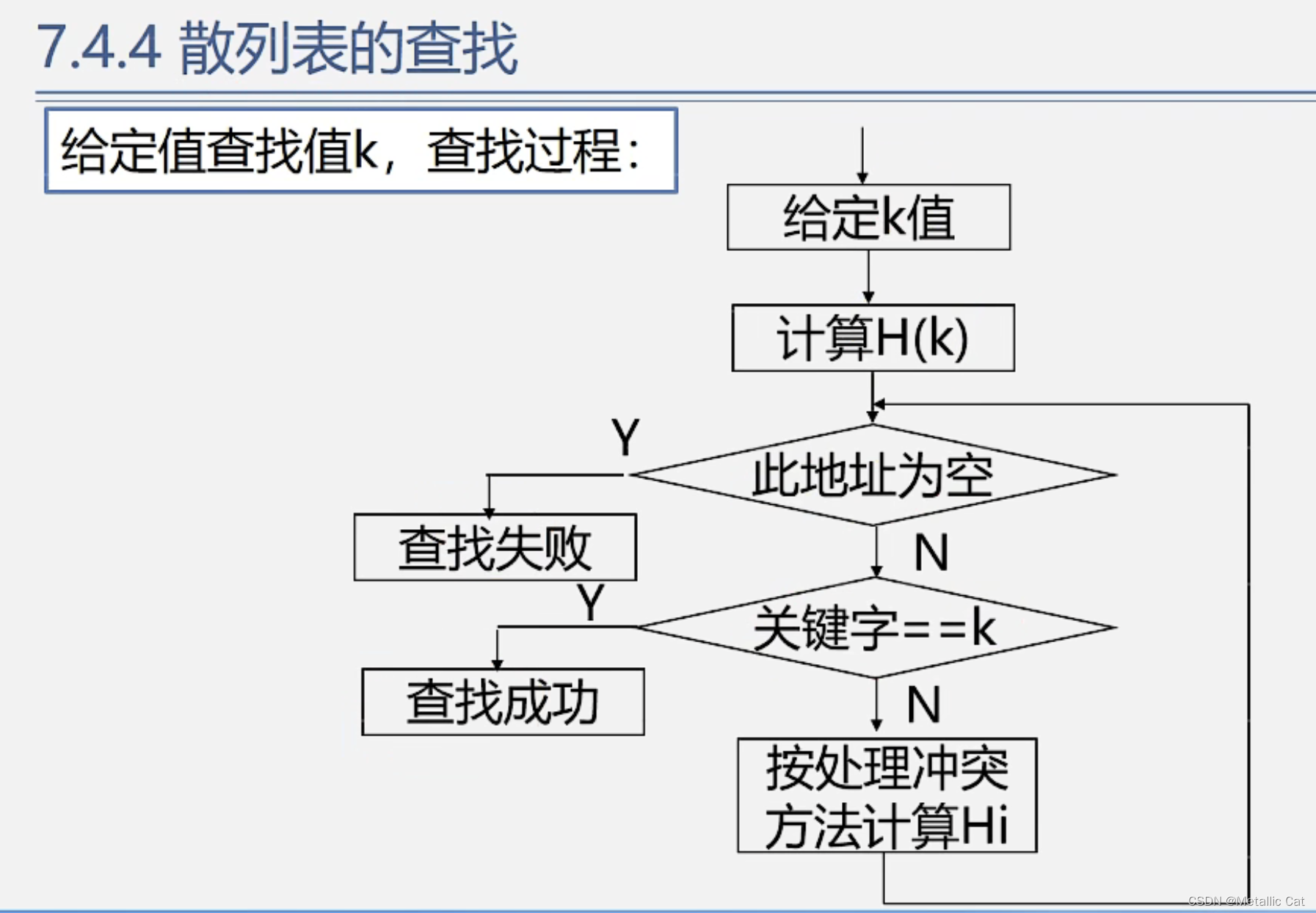
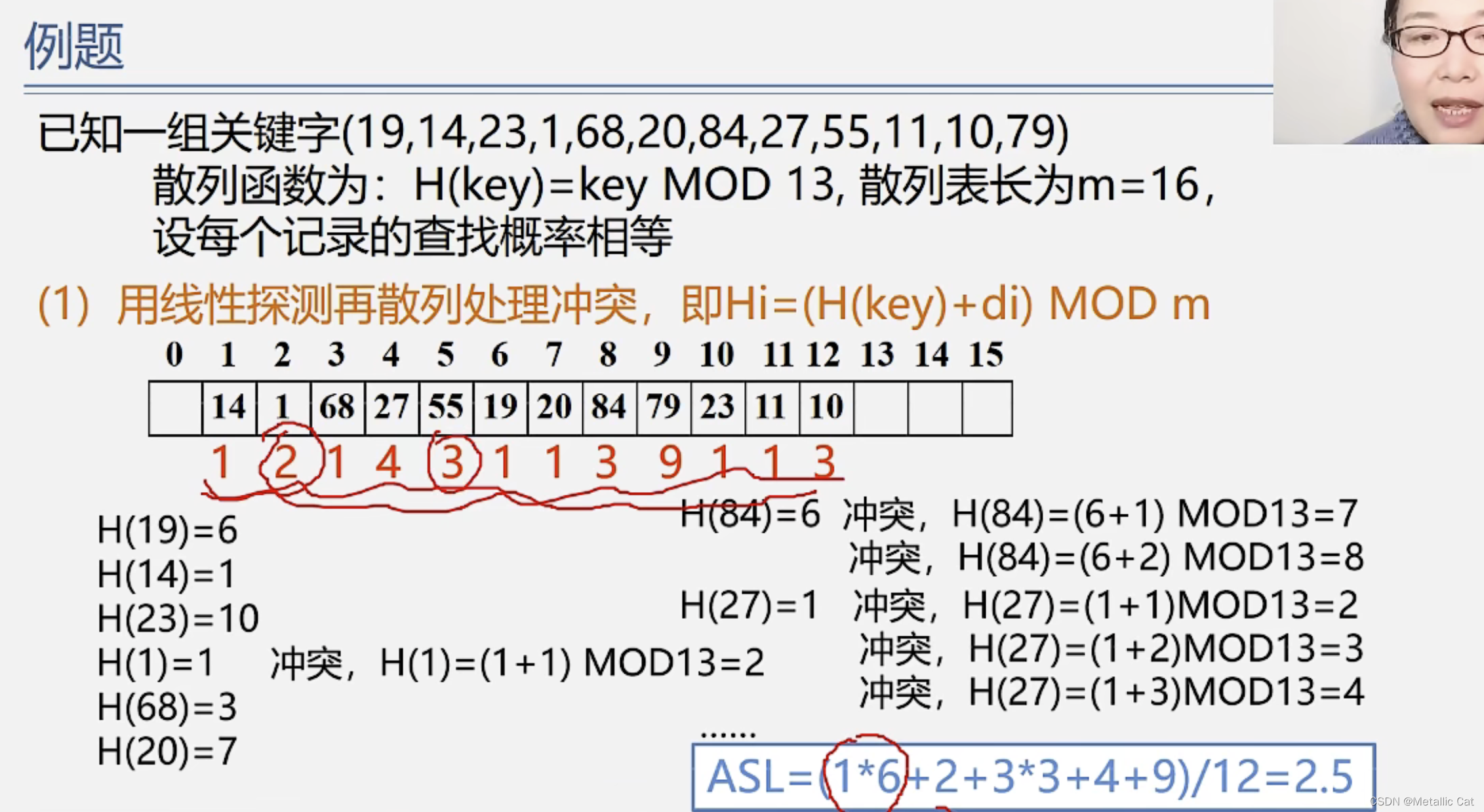
(ASL是每个元素的平均查找长度)
查找散列表中的每一个非空元素所需要的次数就是对应位置下面的红色数字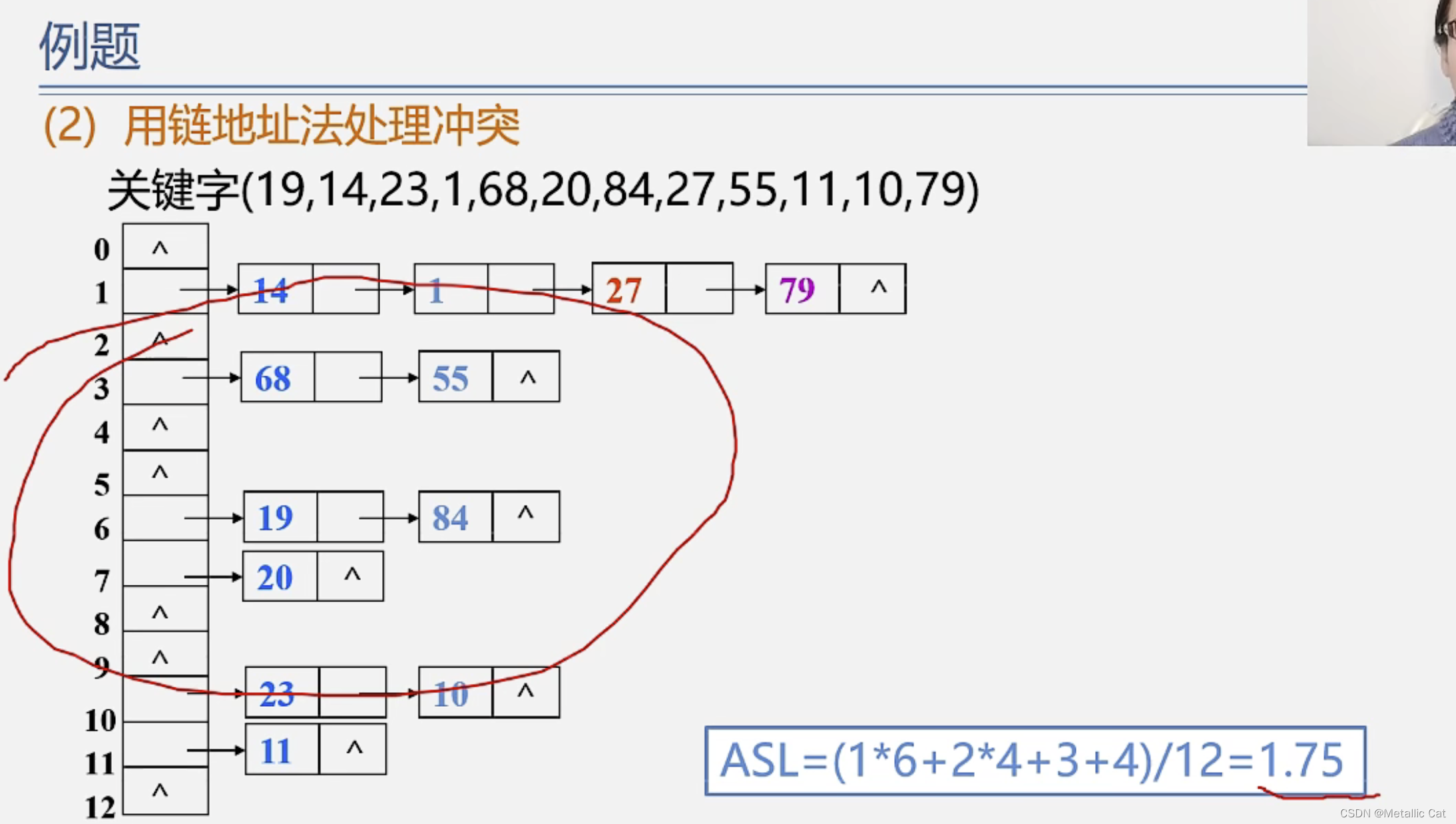
1.用链地址法处理冲突时,平均比较次数能够少的原因是:链地址法采用了空间换时间的模式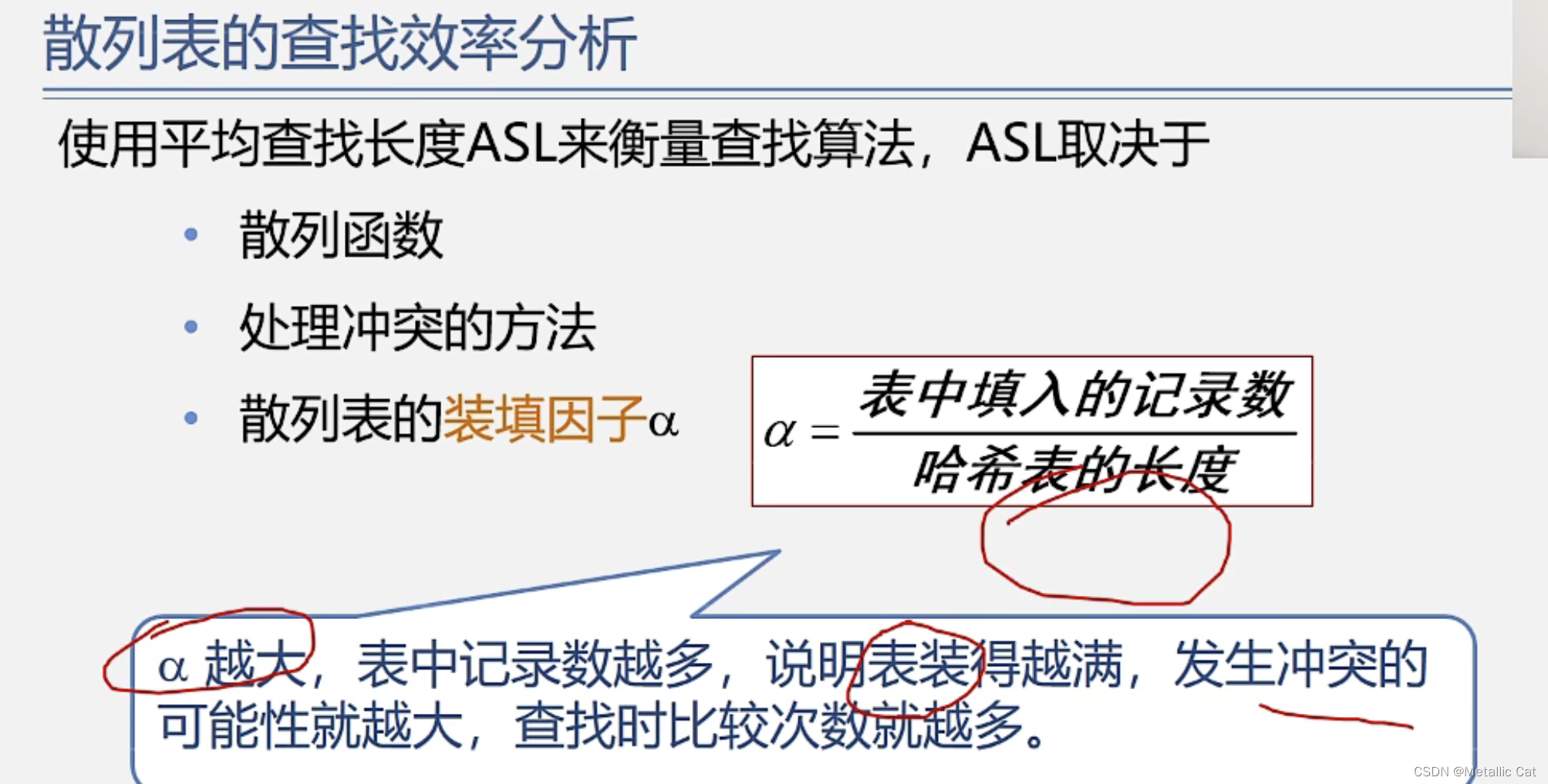
1.表中填入的记录数就等于表中填入的元素数
2.填入的记录数越大,越容易发生冲突,一旦发生冲突就需要解决冲突,而要解决冲突的话必然会涉及到多次比较,查找时的平均比较次数就会增大

1.链地址法除了空间消耗比较多外,它的查找速度快,且是动态的,方便插入和删除元素(记录)